Probability, Statistics, and Data
A Fresh Approach Using R
2021-06-24
Preface
This book represents a fundamental rethinking of a calculus based first course in probability and statistics. We offer a breadth first approach, where the essentials of probability and statistics can be taught in one semester. The statistical programming language R plays a central role throughout the text through simulations, data wrangling, visualizations and statistical procedures. Data sets from a variety of sources, including many from recent, open source scientific articles, are used in examples and exercises. Demonstrations of important facts are given through simulations, with some formal mathematical proofs as well.
This book is an excellent choice for students studying data science, statistics, engineering, computer science, mathematics, science, business, or for any student wanting a practical course grounded in simulations.
The book assumes a mathematical background of one semester of calculus along with some infinite series in Chapter 3. Integrals and infinite series are used for notation and exposition in Chapters 3 and 4, but in other chapters the use of calculus is minimal. Since an emphasis is placed on understanding results (and robustness to departures from assumptions) via simulation, most if not all parts of the book can be understood without calculus. Proofs of many results are provided, and justifications via simulations for many more, but this text is not intended to support a proof based course. Readers are encouraged to follow the proofs, but often one wants to understand a proof only after first understanding the result and why it is important.
Our philosophy in this book is to not shy away from messy data sets. The book contains extensive sections and many exercises that require data cleaning and manipulation. This is an essential part of the text.
A one semester course using this book could reasonably cover most material in Chapters 1-8 in order and then select two or three additional chapters. Sections 2.4, 3.6, 5.6, 8.7 and 8.8 may be omitted or given light coverage. The descriptive statistics in Chapters 6 and 7 are frequently the first part of a statistics course, but we recommend leaving them in the middle as it provides students with a welcome change of pace during the semester. Chapter 9 (Rank Based Tests) is particularly important because it uses simulation techniques developed throughout the text to help students understand power and the effects of assumptions on testing.
There is enough material for a more leisurely and thorough two semester sequence that would delve deeper into probability theory, spend more time on data wrangling, and cover all of the inference chapters.
Most chapters in the book contain at least one vignette. These short sections are not part of the development of the base material. We imagine these vignettes as starting points for further study for some students, or as interesting additions to the main material. Examples include chloropleth maps, data and gender, Stein’s paradox, and a treatment of Covid-19 data.
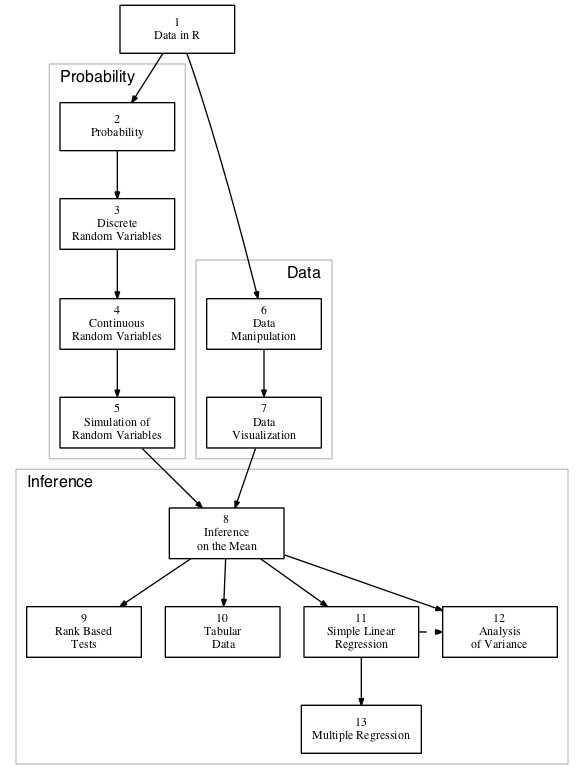
Figure 0.1: Chapter Dependencies
Base R and tidyverse tools are interspersed, depending on which is better for a particular job, though we don’t introduce any tidyverse tools until Chapter 6. We feel that replicate and the base R plotting tools are appropriate for doing simulations and creating the types of visualizations that we need in the first chapters. The dplyr package is used for most data wrangling beginning in Chapter 6, and ggplot2 is used for most visualizations beginning in Chapter 7. Other tidyverse tools introduced in this text, in order of emphasis, are stringr for string manipulation, tidyr for pivot_longer and pivot_wider, lubridate and janitor::clean_names.
All data sets for this book are found in freely available R packages.
The bulk of the data sets are in the package associated to this book, fosdata,
and are mostly sourced from open access publications that are linked to in the help pages of the data.
We encourage readers to spend time reading the publications that were written using the data in the book.
We have taken two approaches to the data from original papers.
In some instances, fosdata provides essentially all of the data from the published paper.
This allows you to explore the data further and think about other visualizations and analyses that would be useful.
It also typically requires some wrangling to get the data in a format for the analysis.
In other instances, we have simplified the data from the paper quite a bit.
In particular, in a few instances we have modified the data by filtering out observations or averaging in order to make it reasonable to assume independence.
Please see the links provided in the help pages of fosdata for details.
No book like this would be complete without resources for the student who wishes to learn more. Here are some suggestions for further study that that the authors have enjoyed:
- ggplot2, by Hadley Wickham, gives a nice overview of the capabilities of the
ggplot2package. Students interested in data visualization would find this book interesting. - Advanced R, by Hadley Wickham, provides much more information on R than what we cover in this book. Computer Science students might enjoy reading this book.
- The Statistical Sleuth, by Ramsey and Schafer, will help the student think more like a statistician when dealing with data sets. This book is on a lower level mathematically.
- Modern Applied Statistics with S, by Venables and Ripley, is a book that covers more advanced statistical topics without much mathematics.
- Introductory Statistics with R, by Peter Dalgaard, is a concise introduction to using R for many types of statistical procedures.
- Mathematical Statistics with Applications, by Wackerly, Mendenhall and Scheaffer, is a more mathematical (but still only requiring multivariate calculus and perhaps basic linear algebra) look at the topics of this book. Students interested in learning how to do the material in this book by hand without access to a computer may enjoy this book.
- Data Feminism by D’Ignazio and Klein offers a way of thinking about data science and data ethics informed by the ideas of intersectional feminism. About more than just gender, this book investigates the use and abuse of the power of data science.
This book is written in R Markdown using the bookdown package, by Yihui Xie. The original idea for a course of this type is due to Michael Lamar. The authors wish to thank Matt Schuelke, Kerith Conron, and Christophe Dervieux for helpful discussions. Thanks to Haijun Gong, Kimberly Druschel, Luis Miguel Anguas, Mustafa Attallah, Xue Li, and Caden Beddingfield for working through early editions. The anonymous reviewers provided useful comments, for which we are also grateful. We wish John Kimmel, our editor at CRC Press, many thanks and a very happy retirement!
This book is copyright 2021, Darrin Speegle and Bryan Clair. Do not transmit or reuse without express permission.
Software Installation
R is a programming language, distributed as its own software program.
To install R:
Mac users
- Visit the CRAN archive, at https://cran.r-project.org
- Find the link that looks like “R-x.x.x.pkg” under the Latest release heading.
- Download the “R-x.x.x.pkg” file, double-click it to open, and follow the installation instructions.
Windows users
- Visit the CRAN archive, at https://cran.r-project.org
- Click on the “Download R for Windows” link at the top of the page.
- Click on the “base” link.
- Click the large “Download R x.x.x for Windows” link and save the executable file somewhere on your computer.
- Run the .exe file and follow the installation instructions.
RStudio is a graphical interface to R. R can work without RStudio, but RStudio requires R to work. Though you may choose to use R in its native form, the improvements that come with RStudio are absolutely worth the effort to install it. In fact, once you have RStudio installed, there is little need to ever run the R program itself.
To install RStudio:
- Go to www.rstudio.com and click on the “Download RStudio” button.
- Click on “Download RStudio Desktop.”
- Click on the version recommended for your system and install it.
Libraries you might choose to install before starting are the tidyverse and the book’s data set fosdata.
With RStudio running, find the Console and type:
install.packages("tidyverse")
install.packages("remotes")
remotes::install_github(repo = "speegled/fosdata")More details on package installation are in Section 1.8.